
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DataGrip
- vscode
- import data
- jupyter
- localhost
- github token
- run sql script
- database
- csv
- 깃 토큰
- error 해결
- Python
- OrCAD 다운로드
- cmd
- 데이터베이스
- 에러
- PHPStorm
- error
- github clone
- console창
- 따옴표 삭제
- clone
- 단축키
- 오류
- Visual Studio Code
- php
- visualstudio code
- MySQL
- 파이썬
- 클론
- Today
- Total
개발 노트
8/18 Package, 데이터 모델링, ER모델, CRUD matrix, 정규화, 삭제이상 본문
8/18 Package, 데이터 모델링, ER모델, CRUD matrix, 정규화, 삭제이상
hayoung.dev 2022. 8. 18. 17:55--과제
-- 1) SEQUENCE 생성
DROP SEQUENCE emp_row_seq;
CREATE SEQUENCE emp_row_seq;
--2) Audit Table 생성
DROP TABLE emp_row_audit;
CREATE TABLE emp_row_audit(
e_id NUMBER(6) CONSTRAINT emp_row_pk PRIMARY KEY,
e_newname VARCHAR2(30),
e_oldname VARCHAR2(30),
e_newsal NUMBER(7,2),
e_oldsal NUMBER(7,2),
e_gubun VARCHAR2(10),
e_date DATE
);
--3) Trigger emp_row_aud3생성
CREATE OR REPLACE TRIGGER emp_row_aud3
AFTER INSERT OR UPDATE OR DELETE ON emp
FOR EACH ROW
BEGIN
-- IF INSERTING THEN
-- INSERT INTO emp_row_audit
-- VALUES(emp_row_seq.NEXTVAL, :new.ename, NULL, :new.sal, NULL, 'inserting', SYSDATE);
-- ELSIF UPDATING THEN
-- INSERT INTO emp_row_audit
-- VALUES(emp_row_seq.NEXTVAL, :new.ename, :old.ename, :new.sal, :old.sal, 'updating', SYSDATE);
-- ELSIF DELETING THEN
-- INSERT INTO emp_row_audit
-- VALUES(emp_row_seq.NEXTVAL, Null, :old.ename, NULL, :old.sal, 'deleting', SYSDATE);
IF INSERTING THEN
INSERT INTO emp_row_audit(e_id, e_newname, e_newsal, e_gubun, e_date)
VALUES(emp_row_seq.NEXTVAL, :new.ename, :new.sal, 'inserting', SYSDATE);
ELSIF UPDATING THEN
INSERT INTO emp_row_audit(e_id, e_newname, e_oldname, e_newsal, e_oldsal, e_gubun, e_date)
VALUES(emp_row_seq.NEXTVAL, :new.ename, :old.ename, :new.sal, :old.sal, 'updating', SYSDATE);
ELSIF DELETING THEN
INSERT INTO emp_row_audit(e_id, e_oldname, e_oldsal, e_gubun, e_date)
VALUES(emp_row_seq.NEXTVAL, :old.ename, :old.sal, 'deleting', SYSDATE);
END IF;
END;
INSERT INTO emp(empno, ename, sal, deptno)
VALUES(3500, '김현진', 3500, 50);
INSERT INTO emp(empno, ename, sal, deptno)
VALUES(3600, '박은주', 3500, 50);
UPDATE emp
SET ename = '은주',
sal = 3700
WHERE empno = 3600;
DELETE emp WHERE empno = 9999;실행 후 emp_row_audit 테이블 모습

Package
자주 사용하는 프로그램과 로직을 모듈화. procedure와 function 등을 말함.
응용 프로그램을 쉽게 개발할 수 있음
프로그램의 처리 흐름을 노출하지 않아 보안 기능이 좋음
프로그램에 대한 유지보수 작업이 편리
같은 이름의 프로시저와 함수를 여러 개 생성
PACKAGE(패키지) 문법

-- 1.Header --> 역할 : 선언 (Interface 역할)
-- 여러 PROCEDURE 선언 가능
CREATE OR REPLACE PACKAGE emp_info AS
PROCEDURE all_emp_info; -- 모든 사원 정보
PROCEDURE all_sal_info; -- 부서별 급여 정보
PROCEDURE dept_emp_info (p_deptno IN dept.deptno%TYPE); --특정 부서의 사원 정보
END emp_info;
--2. Body 역할 : 실제 구현
CREATE OR REPLACE PACKAGE BODY emp_info AS
-----------------------------------------------------------------
-- 모든 사원의 사원 정보(사번, 이름, 입사일)
-- 1. CURSOR : emp_cursor
-- 2. FOR IN
-- 3. DBMS -> 각각 줄 바꾸어 사번,이름,입사일
-----------------------------------------------------------------
PROCEDURE all_emp_info
IS
CURSOR emp_cursor IS
SELECT empno, ename, to_char(hiredate, 'YYYY/MM/DD') hiredate
FROM emp
ORDER BY hiredate;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR emp IN emp_cursor LOOP
DBMS_OUTPUT.PUT_LINE('사번 : ' || emp.empno);
DBMS_OUTPUT.PUT_LINE('이름 : ' || emp.ename);
DBMS_OUTPUT.PUT_LINE('입사일 : ' || emp.hiredate);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM || '에러 발생');
END all_emp_info;
-- 모든 사원의 부서별 급여 정보
-- 1. CURSOR : empdept_cursor
-- 2. FOR IN
-- 3. DBMS -> 각각 줄 바꾸어 부서명 ,전체급여평균 , 최대급여금액 , 최소급여금액
PROCEDURE all_sal_info
IS
CURSOR empdept_cursor IS
SELECT d.dname dname, round(AVG(e.sal), 3) avg_sal, MAX(e.sal) max_sal, MIN(e.sal) min_sal
FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY d.dname;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR empdept IN empdept_cursor LOOP
DBMS_OUTPUT.PUT_LINE('부서명 : ' || empdept.dname);
DBMS_OUTPUT.PUT_LINE('전체급여평균 : ' || empdept.avg_sal);
DBMS_OUTPUT.PUT_LINE('최대급여금액 : ' || empdept.max_sal);
DBMS_OUTPUT.PUT_LINE('최소급여금액 : ' || empdept.min_sal);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM||'에러 발생 ' );
END all_sal_info;
--특정 부서의 해당하는 사원 정보 PROCEDURE dept_emp_info
-- 1. PARAMETER(p_deptno)
-- 2. CURSOR : empindept_cursor
-- 3. FOR IN
-- 4. DBMS -> 특정 부서의 해당하는 사원 사번,이름, 입사일
PROCEDURE dept_emp_info (p_deptno IN dept.deptno%TYPE)
IS
CURSOR empindept_cursor IS
SELECT empno, ename, to_char(hiredate, 'YYYY/MM/DD') hiredate
FROM emp
WHERE deptno = p_deptno
ORDER BY hiredate;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR emp IN empindept_cursor LOOP
DBMS_OUTPUT.PUT_LINE('사원 사번 : ' || emp.empno);
DBMS_OUTPUT.PUT_LINE('이름 : ' || emp.ename);
DBMS_OUTPUT.PUT_LINE('입사일 : ' || emp.hiredate);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM || '에러 발생');
END dept_emp_info;
END emp_info;
*패키지 우클릭 > PL/SQL 블록을 바깥 scott에서 쿼리문으로 실행시킬 수도 있다.
BEGIN
EMP_INFO.ALL_EMP_INFO();
rollback;
END;
emp_info 패키지 우클릭 > all_emp_info 실행

실행 결과

all_sal_info 실행 결과

dept_emp_info 실행 결과 (20 입력)

데이터 모델링의 구성 요소


1) 요구사항을 알아야 개념적 모델링을 할 수 있다.
2) 영업을 하는 데에는 거래처명, 거래처 번호, 거래처 품명, 매출액, 부가세 등등이 필요하며 이런 것을 모아둔 것을 개념적 구조라고 한다. 이것을 하나의 테이블처럼 관리 하는 것을 개념적 모델링이라고 한다.
3) 위의 데이터들을 구조적으로 만드는 것을 논리적 구조라고 한다. 이를 분석하는 것이 논리적 모델링이다. 이 단계에서 정규화, 참조 무결성 규칙, PK, check 조건 등등 규칙을 정의한다.
4) 그 데이터들을 oracle, mysql 등에 맞게 테이블을 구체적으로 만들어서 확정시키고 스크립트를 사용할 수 있는 단계가 물리적 모델링이다.
물리적 모델링에서 테이블(table)은 개념적 모델링에서는 엔티티(Entity)라고 한다.
물리적 모델링에서 칼럼(column)은 개념적 모델링에서는 어트리뷰트(Attribute)라고 한다.

[데이터모델링]
(중요 : CRUD matrix 문제 나올 수도 있음)


사원 테이블은 필요없는 테이블일 수 있다.

데이터를 추가하거나 삭제할 수 없는 테이블이라면 테이블을 생성할 때 하드코딩으로 생성하며 앞으로 전혀 추가, 수정, 삭제가 없는 테이블인지를 확인하기.
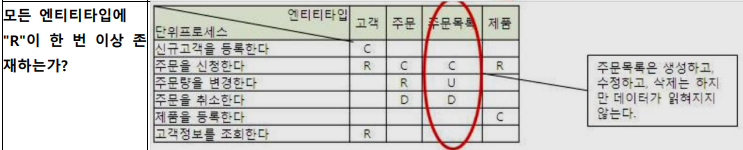
read가 없는 경우 주문 목록이 정말 조회할 필요가 없는 테이블인가를 확인하기

한 테이블을 여러군데에서 read 할 수 있지만(문제가 없지만) 한 테이블에서 create가 여러개라면 한 군데로 통합해서 insert를 한 번만 하는 것이 맞다. 두 곳에서 한 테이블로 insert를 하면 문제가 생길 수 있음.
(중요 : 면접 질문에 나올 수 있음)
정규화(Normalization)의 정의 : 데이터의 중복성을 제거하여 이상현상을 방지하는 것
이상현상의 종류
삭제 이상 : 한 튜플을 삭제함으로써 유지해야 할 정보까지 삭제되는 연쇄삭제(triggered deletion) 현상이 일어나게 되어 정보손 실이 발생하게 되는 현상
삽입 이상 : 어떤 데이터를 삽입하려고 할 때 불필요하고 원하지 않는 데이터도 함께 삽입해야 하고 그렇지 않으면 삽입이 되지 않는 현상
갱신 이상 : 중복된 튜플 중 일부 튜플의 어트리뷰트 값만을 갱신하여 정보의 모순성이 생기는 현상

(면접에는 안나오지만 기사시험에는 나온다)
재귀 법칙: a가 b를 포함하면 a가 b를 종속한다.
증가 법칙 : a가 b를 종속할 때 ac는 bc를 종속한다.
이행 규칙 : a가 b를 종속하고 b가 c를 종속하면 a가 c를 종속한다.
연합 규칙 : a가 b를 종속하고 a가 c를 종속하면 a는 bc를 종속한다.
분해 규칙 : a가 bc를 종속하면 a가 b를 종속하고 a가 c를 종속한다.
가이행 규칙 : a가 b를 종속하고 bc가 d를 종속하면 ac는 d를 종속한다.

(중요 : 면접에서 정규화 가끔 물어봄. 알아두는 것이 좋음)
관계형 DB 설계 시 테이블스키마(R)와 함수종속성(FD)이 아래와 같을 때
R(A, B, C, D, E, F, G, H, I)
FD : A -> B, A -> C, D -> E, AD -> I, D -> F, F -> G, AD -> H
FDD는 FD를 그림으로 그린 것. 이렇게 그리는 것이 권장. 한눈에 들어와서 정규화를 하기 쉬워지기 때문.

1차 정규화는 모든 속성을 종속하는 것이다. primary key를 도출하는 것.
A, D -> B, C, E, F, G, H, I
2차 정규화 : 부분 함수 종속
primary key가 복합키(2개 이상일 때) 각각 종속하는 것이 달라서 일어남.
D -> E, F, G
A, D -> H, I
A -> B, C
3차 정규화 : 이행 함수 종속
primary key가 아닌 것을 종속할 때 (F -> G)
F-> G
D -> E, F
A, D -> H, I
A -> B, C
총 테이블이 4개가 된다.
테이블 1(F-> G)과 2(D -> E, F)는 약연결
테이블 2(D -> E, F)와 3(A, D -> H, I)은 강연결(Primary key와의 연결이기 때문)
'프로젝트 기반 JAVA 응용 SW개발 : 22.07.19~23.01.20 > Oracle SQL' 카테고리의 다른 글
| 8/22 KK 영업매출현황 패키지(KK_COLLECTION_PKG) 제작 (0) | 2022.08.22 |
|---|---|
| 8/19 정규화, KK 영업매출현황 TABLE 생성, KK_COLLECTION_PKG 제작(1) (0) | 2022.08.19 |
| 8/17 데이터베이스 보안, 권한, 롤, WITH GRANT OPTION, REVOKE, 동의어, Trigger (0) | 2022.08.18 |
| 8/16 PL/SQL, Function, Procedure, Cursor, Exception (0) | 2022.08.17 |
| 8/12 Oracle Backup 하는 법 (0) | 2022.08.17 |



